This is a part of a series of blog posts on data access with Dapper. To see the full list of posts, visit the Dapper Series Index Page.
Update: April 16, 2018 Something really cool happened in the comments. The amazing Phil Bolduc very kindly pointed out that the query I wrote was not optimal and as a result, my benchmarks were not showing the best results. He didn’t stop there, he also submitted a pull request to the sample repo so I could rerun my benchmarks. Great job Phil and thanks a ton for being constructive in the comments section! I have updated the post to include Phil’s superior query.
In today’s post, we look at another option for how to load Many-to-One relationships. In the last post, we used a technique called Multi-Mapping to load related Many-to-One entities. In that post, I had a theory that maybe this approach was not the most efficient method for loading related entities because it duplicated a lot of data.
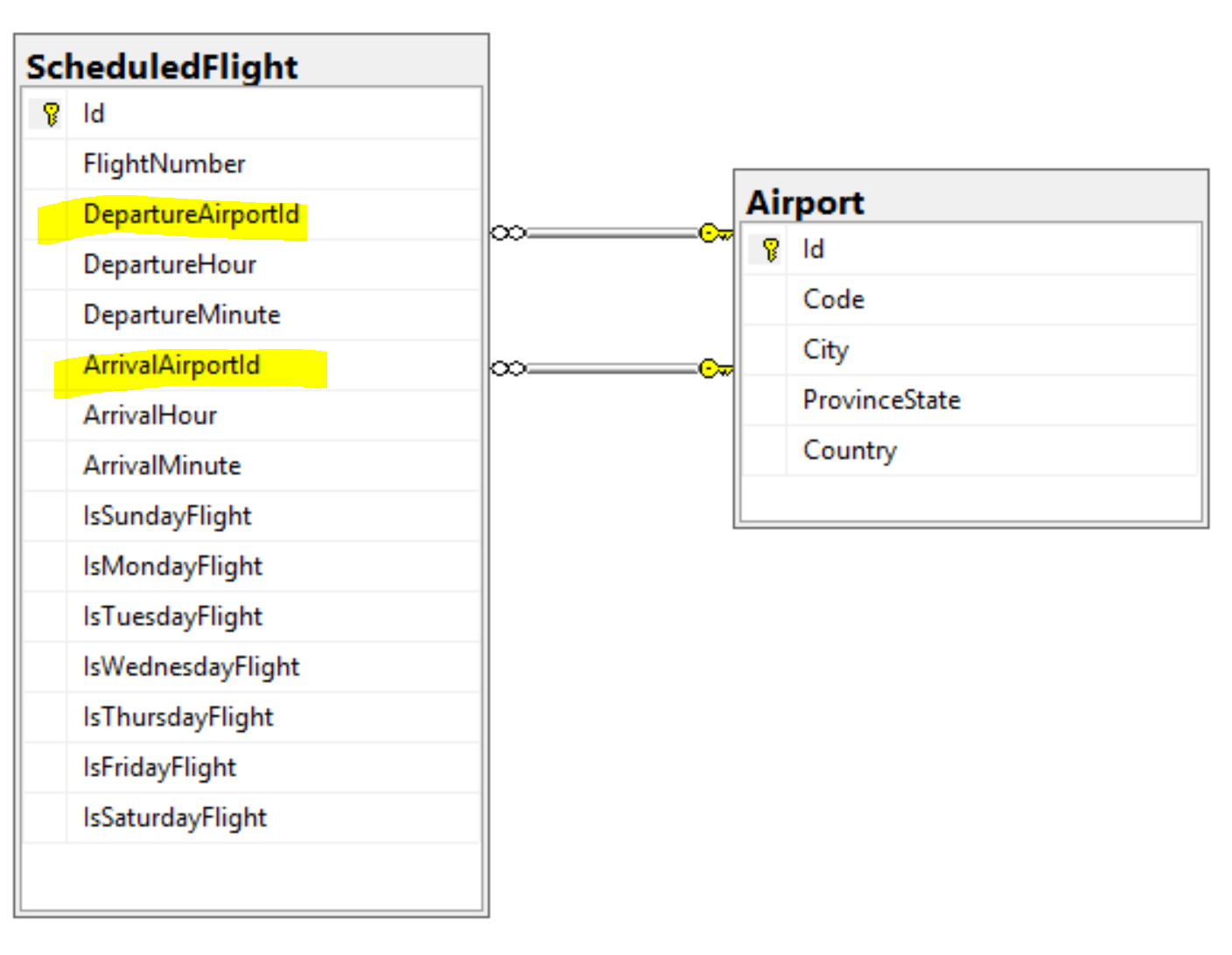
To recap, we would like to load a list of ScheduledFlight entities. A ScheduleFlight has a departure Airport and an arrival Airport.
public class ScheduledFlight |
Using Multiple Result Sets
In the previous post, we loaded the ScheduledFlight entities and all related Airport entities in a single query. In this example we will use 2 separate queries: One for the ScheduledFlight entities, one for the related arrival and departure Airport entities. These 2 queries will all be executed as a single sql command that returns multiple result sets.
SELECT s.Id, s.FlightNumber, s.DepartureHour, s.DepartureMinute, s.ArrivalHour, s.ArrivalMinute, s.IsSundayFlight, s.IsMondayFlight, s.IsTuesdayFlight, s.IsWednesdayFlight, s.IsThursdayFlight, s.IsFridayFlight, s.IsSaturdayFlight, |
Using Dapper’s QueryMultipleAsync method, we pass in 2 arguments: the query and the parameters for the query.
public async Task<IEnumerable<ScheduledFlight>> GetAlt(string from) |
The QueryMultipleAsync method returns a GridReader. The GridReader makes it very easy to map multiple result sets to different objects using the Read<T> method. When you call the Read<T> method, it will read all the results from the next result set that was returned by the query. In our case, we call Read<ScheduledFlight> to read the first result set and map the results into a collection of ScheduledFlight entities. Next, we call Read<Airport> to read the second result set. We then call ToDictionary(a => a.Id) to populate those Airport entities into a dictionary. This is to make it easier to read the results when setting the ArrivalAirport and DepartureAirport properties for each ScheduledFlight.
Finally, we iterate through the scheduled flights and set the ArrivalAirport and DepartureAirport properties to the correct Airport entity.
The big difference between this approach and the previous approach is that we no longer have duplicate instances for Airport entities. For example, if the query returned 100 scheduled flights departing from Calgary (YYC), there would be a single instance of the Airport entity representing YYC, whereas the previous approach would have resulted in 100 separate instances of the Airport entity.
There is also less raw data returned by the query itself since the columns from the Airport table are not repeated in each row from the ScheduleFlight table.
Comparing Performance
I had a theory that the multi-mapping approach outlined in the previous blog post would be less efficient than the multiple result set approach outlined in this blog post, at least from a memory usage perspective. However, a theory is just theory until it is tested. I was curious and also wanted to make sure I wasn’t misleading anyone so I decided to test things out using Benchmark.NET. Using Benchmark.NET, I compared both methods using different sizes of data sets.
I won’t get into the details of Benchmark.NET. If you want to dig into it in more detail, visit the official site and read through the docs. For the purposes of this blog post, the following legend should suffice:
Mean : Arithmetic mean of all measurements |
10 ScheduledFlight records
| Method | Mean | Error | StdDev | Gen 0 | Allocated |
|---|---|---|---|---|---|
| MultiMapping | 397.5 us | 3.918 us | 4.192 us | 5.8594 | 6.77 KB |
| MultipleResultSets | 414.2 us | 6.856 us | 6.077 us | 4.8828 | 6.69 KB |
As I suspected, the difference is minimal when dealing with small result sets. The results here are in microseconds so in both cases, executing the query and mapping the results takes less 1/2 a millisecond. The multiple result sets approach takes a little longer, which I kind of expected because of the overhead of creating a dictionary and doing lookups into that dictionary when setting the ArrivalAirport and DepartureAirport properties. The difference is minimal and in a most real world scenarios, this won’t be noticeable. What is interesting is that even with this small amount of data, we can see that there is ~1 more Gen 0 garbage collection happening per 1,000 operations. I suspect we will see this creep up as the amount of data increases.
100 ScheduledFlight records
| Method | Mean | Error | StdDev | Gen 0 | Allocated |
|---|---|---|---|---|---|
| MultiMapping | 926.5 us | 21.481 us | 32.804 us | 25.3906 | 6.77 KB |
| MultipleResultSets | 705.9 us | 7.543 us | 7.056 us | 15.6250 | 6.69 KB |
When mapping 100 results, the multiple result sets query is already almost 25% faster. Keep in mind though that both cases are still completing in less than 1ms so this is very much still a micro optimization (pun intended). Either way, less than a millisecond to map 100 records is crazy fast.
1000 ScheduledFlight records
| Method | Mean | Error | StdDev | Gen 0 | Gen 1 | Allocated |
|---|---|---|---|---|---|---|
| MultiMapping | 5.098 ms | 0.1135 ms | 0.2720 ms | 148.4375 | 70.3125 | 6.77 KB |
| MultipleResultSets | 2.809 ms | 0.0549 ms | 0.0674 ms | 109.3750 | 31.2500 | 6.69 KB |
Here we go! Now the multiple result sets approach finally wins out, and you can see why. There are way more Gen 0 and Gen 1 garbage collections happening per 1,000 operations when using the multi-mapping approach. As a result, the multiple result sets approach is nearly twice as fast as the multi mapping approach.
10,000 ScheduledFlight records
| Method | Mean | Error | StdDev | Gen 0 | Gen 1 | Gen 2 | Allocated |
|---|---|---|---|---|---|---|---|
| MultiMapping | 56.08 ms | 1.5822 ms | 1.4026 ms | 1687.5000 | 687.5000 | 187.5000 | 6.78 KB |
| MultipleResultSets | 24.93 ms | 0.1937 ms | 0.1812 ms | 843.7500 | 312.5000 | 125.0000 | 6.69 KB |
One last test with 10,000 records shows a more substantial difference. The multiple result sets approach is a full 22ms faster!
Wrapping it up
I think that in most realistic scenarios, there is no discernable difference between the 2 approaches to loading many-to-one related entities. If you loading larger amounts of records into memory in a single query, then the multiple result sets approach will likely give you better performance. If you are dealing with < 100 records per query, then you likely won’t notice a difference. Keep in mind also that your results will vary depending on the specific data you are loading.